On large and small language models
Hex is technically a network of small language models, where each model has been fine tuned to solve specific problems. Hex typically leverages models in the range of 15 billion to 20 billion parameters, although Hex uses larger reasoning models on occasion. This compares to OpenAI’s 1.4 trillion plus parameter model.
Of course the secret sauce for consistency and addressing nefarious issues like hallucination is a function of the quality of the examples (retrieval augmentation generation data/process) and model fine-tuning. We have developed a unique approach for crafting engaging the property and developing these examples. In addition, we have developed a casino specific retrieval protocol: another key foundation.
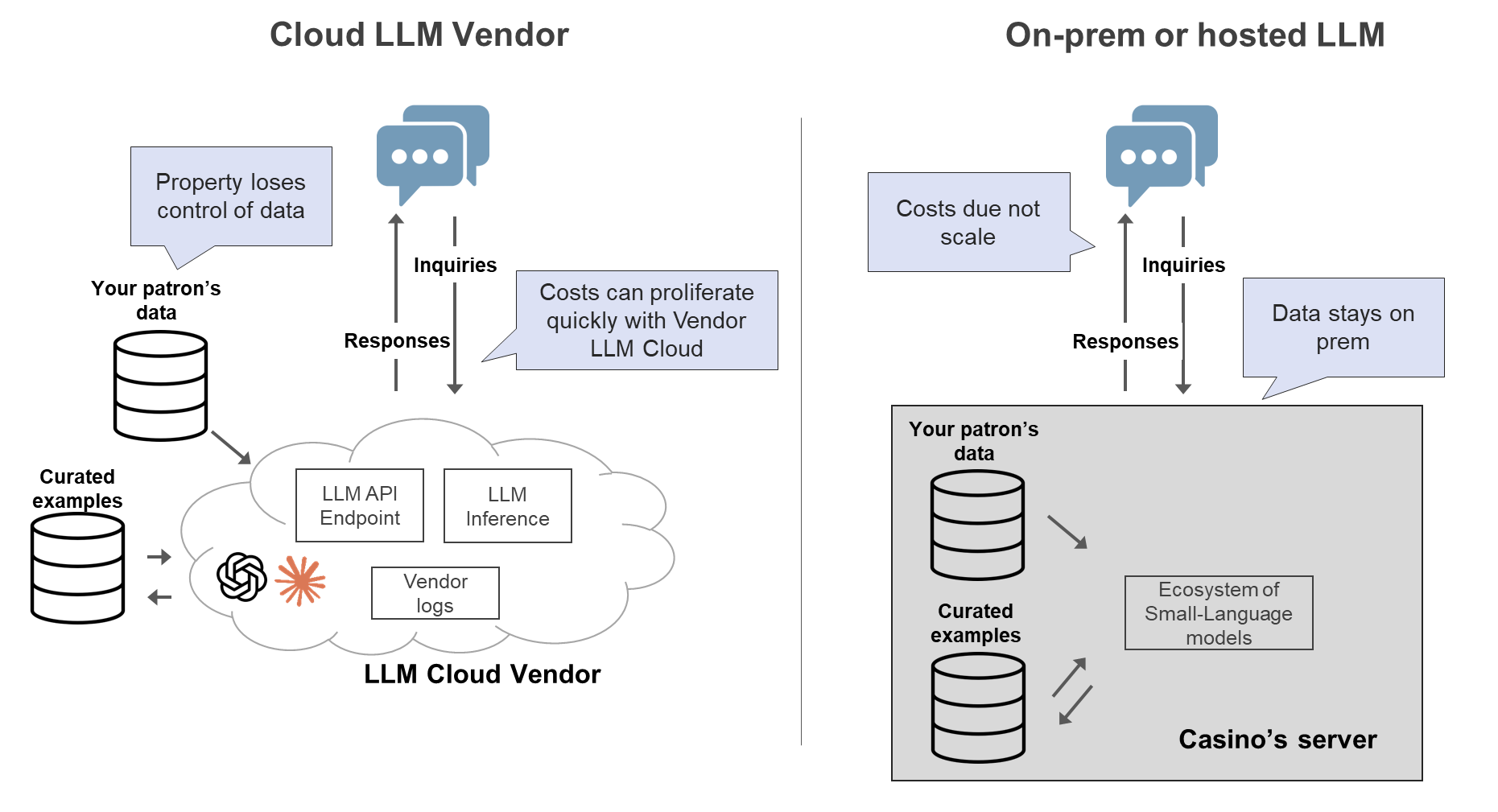
On-prem or hosted small-language models have one major downside and several upsides. The downside is that a small-language model have less dexterity and do not generalize as well as large-language models. As such small language models are best suited to specific tasks. Upsides of on-prem/hosted small language models include that the data never leaves the custody, model can be fine-tuned in many ways, deeper degree of customization, more real-time and less brittle. Implementation of small-language models and be perilous and we developed the casino industry’s first LLM bench marking.
Hex is designed to either be accessed and used directly or more commonly embedded in a property’s existing CRM system.